
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- Machine Learning
- 부스트캠프ai
- deep learning
- Learning rate Scheduler
- 인공지능 그랜드 챌린지
- 음성인식
- Lr Scheduler
- aitech
- End-To-End
- ai
- VAD
- 네이버커넥트재단
- 머신러닝
- 인공지능
- Cosine annealing
- 딥러닝
- 부스트캠프
- Today
- Total
AI4NLP
1. End-to-End Automatic Speech Recognition 개요 본문
이 카테고리는 종단간 자동 음성 인식(End-to-End Automatic Speech Recognition, 이하 E2E ASR)에 대해 작성하는 연작 포스팅입니다.
주요 표기법(Notation)과 내용(Content)은 Speech and Language Processing 2nd Edition(Daniel Jurafsky and James H. Martin) 을 참고하여서 작성하였습니다.
첫 포스팅에서는 자동음성인식( Automatic Speech Recognition, 이하 ASR)의 문제 정의와 접근 방법들의 개요를 작성해보고자 합니다.

ASR의 정의
ASR은 사람이 말하는 음성 파형(아날로그)을 컴퓨터가 자동으로 문자 데이터(디지털)로 변환하는 기술입니다. Speech-To-Text, STT라고도 불리기도 합니다. ASR은 우리가 사용하는 핸드폰의 인공지능 비서, 인공지능 스피커 등에도 들어가는 기술이며, 사람과 컴퓨터의 소통을 위해서 반드시 필요한 기술입니다.
ASR의 목적
ASR은 길이 T의 음향 입력($o_{1},o_{2},...,o_{t}$)에서 길이 N의 레이블 출력($w_{1},w_{2},...,w_{n}$)을 얻어내는 Task입니다. 여기서 입력과 출력의 표기가 다른 이유는 실제로 입력의 길이와 출력의 길이가 다르기 때문($T \neq N$)입니다. 아래 수식은 ASR의 목적을 나타낸 것입니다.
$$\hat{W}=\underset{\rm W\in V}{\rm argmax}P(W|O)$$
O는 음향 입력이며 주로 MRCG(Multi-Resolution Cochleagram), MFCC(Mel-frequency cepstrum)와 같은 feature가 사용됩니다. W는 $o_{t}$에 대응되는 레이블이며, 문자(character) 또는 단어(word) 등이 사용됩니다. V는 가능한 출력값들의 집합이며, NLP에서 사용하는 단어 사전(vocabulary dictionary)과 같다고 보셔도 무방합니다. 입력 시퀀스에 대해 $\hat{W}$을 모델링하는 ASR의 경우는 Large vocabulary continuous speech recognition(LVCSR)이라고도 부릅니다.
간단히 말해서, ASR의 목적은 사후 분포, $P(W|O)$ 값을 최대화하는 $\hat{W}$ 계산하는 수 있는 모델을 만드는 것입니다.
End-to-End ASR과 기존 ASR 비교
기존 ASR에서는 P(W|O)를 모델링하기 위해 은닉 마르코프 모델-가우시안 혼합 모델(HMM-GMM)을 사용했었습니다. 하지만 딥러닝이 발달하면서, 은닉 마르코프 모델 - 심층 신경망 모델(HMM-DNN)과 딥러닝 기반의 종단간 모델(End-to-End)을 사용하기 시작하였고, 실제 두 모델들은 HMM-GMM 보다 더 좋은 성능을 보여주었습니다.
End-to-End ASR에 대해 이야기하기에 앞서 End-to-End ASR 모델과 기존 ASR 모델의 차이에 대해 짚고 가보겠습니다.
HMM based ASR
HMM 기반의 ASR 모델은 음향(Acoustic), Lexicon, 언어(Language) 모델 3가지 부분으로 나누어지며. 각 부분들은 서로 독립적으로 모델링됩니다.
$$\underset{\rm W\in V}{\rm argmax}P(W|O) =\ \underset{\rm W\in V}{\rm argmax}\frac{P(W,O)}{P(O)}$$
$$\qquad \qquad \qquad\quad=\underset{\rm W\in V}{\rm argmax} \ P(W,O)$$
$$\qquad \qquad \qquad\qquad\qquad=\underset{\rm W\in V}{\rm argmax}\sum_{S}P(W,S,O)$$
$$\qquad \qquad \qquad\qquad\qquad\qquad\qquad\qquad=\underset{\rm W\in V}{\rm argmax}\sum_{S}P(O|W,S)P(S|W)P(W)$$
여기에서 조건부 독립 가정에 의해 P(O|W,S)를 P(O|S)로 근사할 수 있습니다. 따라서 HMM의 계산 과정은 아래와 같이 쓸 수 있습니다.
$$\underset{\rm W\in V}{\rm argmax}P(W|O) \approx\ \underset{\rm W\in V}{\rm argmax}\sum_{S}P(O|S)P(S|W)P(W)$$
위 식에서 P(O|S)와 P(S|W),P(W)이 각각 음향(Acoustic), Lexicon, 언어(Language) 모델입니다.

HMM 기반의 방법은 음성 인식 Task를 3가지 Task로 나누었기 때문에 나타나는 단점들이 있습니다
- 각각의 모델들에서 최적의 성능을 만들었다 하더라도 이것이 ASR 모델 전체에서 최적의 성능(Global Optima)을 내지 못할 수도 있습니다.
- HMM 계산의 간결성을 위해 조건부 독립을 가정하였는데 이로 인해 실제 계산과의 차이가 생깁니다.
- 음향(Acoustic), Lexicon, 언어(Language) 모델을 각각 구축하는 과정에서 많은 전문 지식이 요구됩니다.
하지만 음향, Lexicon, 언어 3가지 Task로 나누었기 때문에, 다른 도메인에 쉽게 적용시킬 수 있다는 장점도 있습니다.
(예시) 기존 언어 모델을 뉴스 코퍼스에서 학습시킨 언어 모델로 바꿈으로써 전체 음성인식 모델을 뉴스 음성인식에 사용할 수 있음.
End-to-End ASR
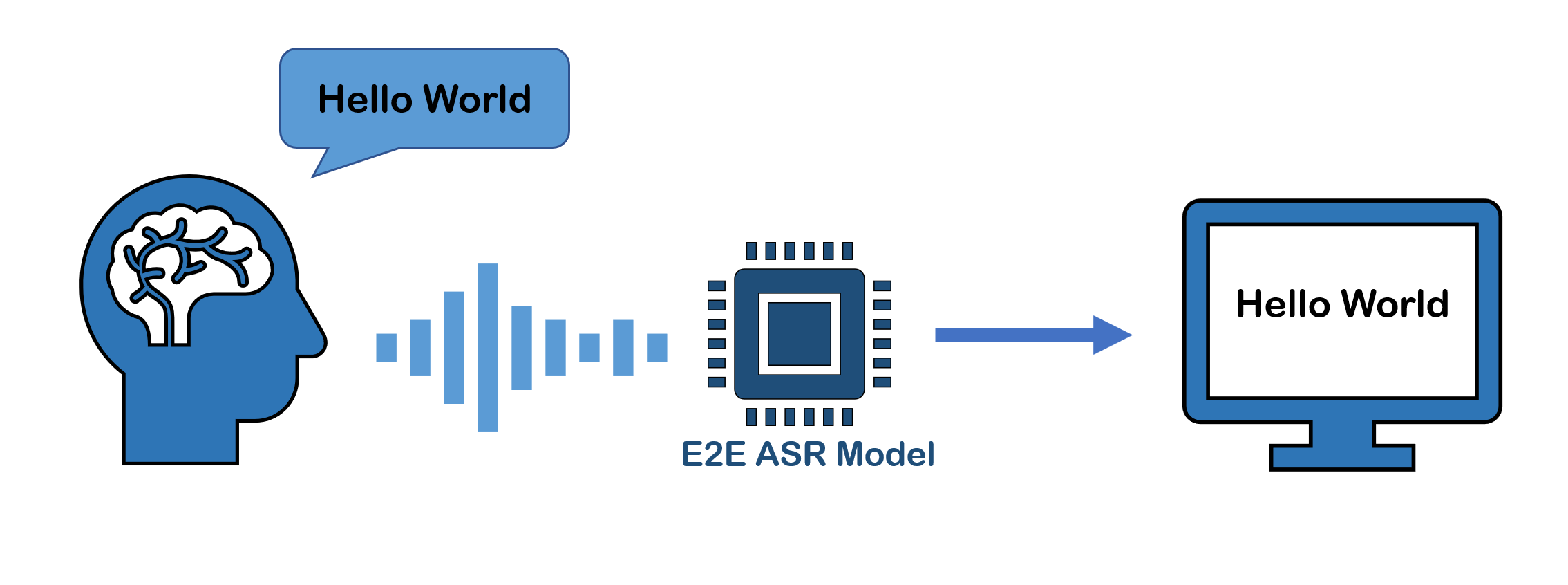
E2E ASR 모델은 음향 입력에서 특징(feature)을 추출하는 특징 추출기(feature extractor)과 feature와 레이블 출력 사이의 정렬(alignment)를 맞추는 부분, 최종 결과를 디코딩하는 디코더로 구성되어있습니다. 하지만 HMM과는 달리 모든 부분들이 별도의 훈련 과정 없이 한번에 함께 훈련됩니다. 그렇기 때문에 별도의 모델링이 필요하지 않고, 목적 함수에 맞는 최적 값(Global Optima)을 얻을 수 있습니다.
딥러닝 기반의 End-to-End 모델은 크게 3가지 범주로 나눌 수 있습니다.
CTC (Connectionist Temporal Classification)
최적의 정렬(Alignment)를 찾아내기 위해 가능한 모든 시퀀스들을 나열한 후, Baum-Welch 알고리즘을 사용하는 알고리즘입니다. CTC의 경우는 출력되는 레이블들이 서로 독립이라는 가정을 한다는 단점이 있습니다.(Conditional Independence)
RNN Transducer
CTC와 마찬가지로 최적의 정렬(Alignment)을 찾아내기 위해 모든 시퀀스를 나열한 후 구합니다. 하지만 CTC와 달리 조건부 독립을 가정하지 않기 때문에 최적 경로 계산이 CTC와는 다르며, CTC보다 더 복잡하게 계산됩니다.
Attention
위의 두 알고리즘과는 달리 Attention 알고리즘을 이용하여 음향 입력과 레이블 출력 사이의 정렬(Alignment)을 계산합니다.
각 범주들에서 Attention 알고리즘과 CTC 알고리즘을 결합하여 만든 joint-CTC/Attention도 있습니다. 추후 포스팅에서 다루겠습니다.
HMM과 비교했을 때, End-to-End의 장점은 다음과 같습니다.
- 출력에 별도의 사후 처리(Post-processing)를 할 필요가 없습니다.
- 여러 모듈들이 하나로 훈련되기 때문에, 전문가들이 모듈을 설계할 필요가 없습니다. 즉, 다루기 쉽습니다.
- 하나의 훈련 과정을 거치기 때문에 최종 성능 기준에 맞는 목적함수를 설정할 수 있고, 이는 최적의 결과(Global Optima)를 보장할 수 있습니다.
다음 포스팅에서는 CTC로 찾아뵙겠습니다.
감사합니다.
'Speech Recognition' 카테고리의 다른 글
| IEEE ICASSP 2021 SELF-ATTENTIVE VAD: CONTEXT-AWARE DETECTION OF VOICE FROM NOISE 후기 및 간단설명 (0) | 2021.01.30 |
|---|---|
| 0. End-to-End ASR 포스팅 작성 계획 (0) | 2020.03.29 |

