
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 네이버커넥트재단
- Lr Scheduler
- 인공지능
- 인공지능 그랜드 챌린지
- Machine Learning
- ai
- deep learning
- Learning rate Scheduler
- Cosine annealing
- 부스트캠프
- 머신러닝
- End-To-End
- 부스트캠프ai
- VAD
- 음성인식
- aitech
- 딥러닝
- Today
- Total
AI4NLP
코싸인 어닐링,Cosine annealing learning rate scheduler 간단 설명 본문
코싸인 어닐링,Cosine annealing learning rate scheduler 간단 설명
nlp user 2020. 12. 13. 21:12
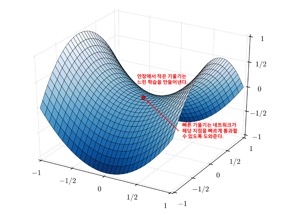
Cosine annealing은 "SGDR: Stochastic Gradient Descent with Warm Restarts"에서 제안되었던 학습율 스케쥴러로서, 학습율의 최대값과 최소값을 정해서 그 범위의 학습율을 코싸인 함수를 이용하여 스케쥴링하는 방법이다. Cosine anneaing의 이점은 최대값과 최소값 사이에서 코싸인 함수를 이용하여 급격히 증가시켰다가 급격히 감소시키 때문에 모델의 매니폴드 공간의 안장(saddle point)를 빠르게 벗어날 수 있으며([그림 1] 참조), 학습 중간에 생기는 정체 구간들 또한 빠르게 벗어날 수 있도록 한다. 결과적으로 이러한 방법이 모델의 일반화 성능을 극대화시켜준다. 논문의 실험 결과에 따르면 Cosine annealing을 이용하여 학습한 wide residual network이 CIFAR-10, CIFAR-100 에서 Cosine annealing을 사용하지 않고 학습한 wide residual network에 비해 테스트 데이터에서 0.5%, 1.0%의 높은 성능을 보여주고 있다.
Cosine annealing의 수식은 (11)와 같다.
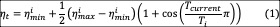
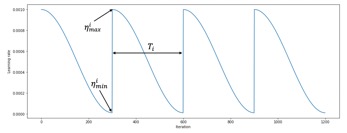
\eta_{t}는 Cosine annealing으로 계산된 현재의 학습률이며, \eta_{min}_{i}, \eta_{max}_{i}는 학습 전에 설정하는 고정된 값으로 각각 학습율의 최소값, 최대값이다. T_{current}는 현재 에폭이며, T_{i}는 Cosine annealing을 실행하는 주기이다. 해당 수식을 나타내면 [그림8]과 같다.
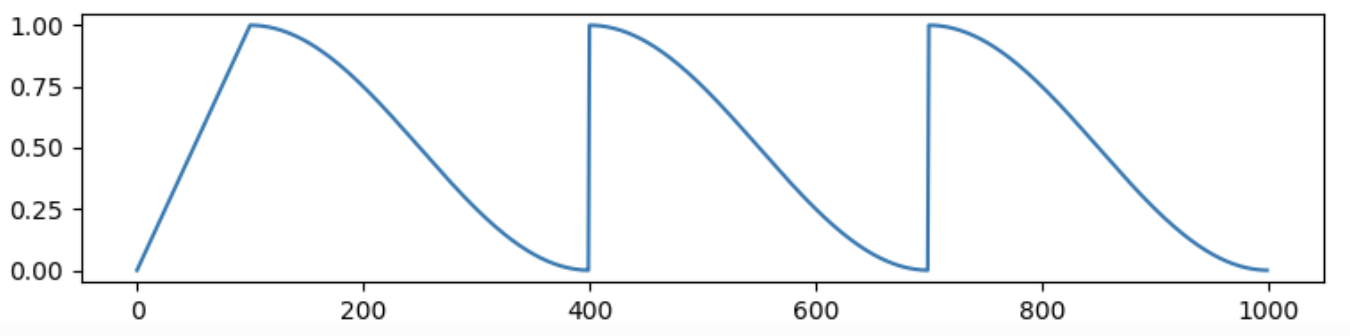
네트워크의 warmup이 필요한 경우는 아래 그림과 같은 형태로도 사용하곤 한다. 참고로 warmup의 경우는 네트워크 파라미터 정렬을 위해 사용하곤 한다. (참고 : transformers.get_cosine_schedule_with_warmup)

개인적으로, Cosine annealing을 트랜스포머(Transformer) 구조와 함께 사용할 때에는 아래와 같은 구조를 사용한다. 트랜스포머 네트워크는 학습 초기에 warmup을 1번 하게 된다. 실제 사용할 때에는 transformers 라이브러리에서 제공하는 transformers.get_cosine_with_hard_restarts_schedule_with_warmup method를 사용하곤 한다.
글의 내용을 간략하게 정리하자면, 웬만하면 학습율 스케쥴러로 Cosine annealing을 쓰는 것을 추천하고 싶다. 그리고 트랜스포머 구조와 함께 사용할 때에는 바로 위의 그림과 같은 구조를 추천하고 싶다. 구현의 경우는 github.com/katsura-jp/pytorch-cosine-annealing-with-warmup 와 huggingface.co/transformers/main_classes/optimizer_schedules.html 를 참조하는 것을 추천한다.
'Machine Learning' 카테고리의 다른 글
| Making Pre-trained Language Models Better Few-shot Learners (0) | 2021.10.24 |
|---|---|
| 따라하며 하는 Slurm 세팅 & 설명, Ubuntu 18.04 (4) | 2021.04.18 |
| GPT-3 paper를 읽고 써보는 간략한 리뷰 혹은 설명, Language Models are Few-Shot Learners (0) | 2020.09.06 |
| 추천 시스템(Recommendation System) - 협업 필터링 (Collaborative filtering) 설명 (1) (0) | 2020.07.19 |
| Learning rate Scheduler 설명 (0) | 2020.06.21 |

