
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- Lr Scheduler
- 인공지능 그랜드 챌린지
- ai
- 음성인식
- 네이버커넥트재단
- 딥러닝
- 부스트캠프ai
- Learning rate Scheduler
- deep learning
- 인공지능
- 머신러닝
- aitech
- VAD
- 부스트캠프
- End-To-End
- Machine Learning
- Cosine annealing
- Today
- Total
AI4NLP
Making Pre-trained Language Models Better Few-shot Learners 본문
Making Pre-trained Language Models Better Few-shot Learners
nlp user 2021. 10. 24. 22:011. 시작
해당 논문은 ACL 2021에 long paper로 accept된 논문입니다.
GPT에서 제시하였던 prompt tuning 방식은 기존 BERT와 같은 pretrain model에서 fine tuning하는 방식과는 다른, 하지만 더 높은 few-shot performance를 보여주며 주목을 받았던 바 있다.
기존 논문들에서는 prompt-based fine-tuning을 위해 prompt(template,label word)와 demonstration을 수동으로 작성해주었다.
하지만, 이렇게 수동으로 직접 prompt와 demonstration을 작성해야한다는 것은 fine-tuning하고자 하는 task의 domain 지식과 많은 시간들을 요구한다는 단점이 있었다.
해당 논문에서는 prompt-based fine-tuning에 필수인 prompt와 demonstration을 자동으로 생성해주는 방법(LM-BFF)을 제시하고, 제시하는 방법을 다른 기존의 방법들과 비교하는 실험을 진행하였다. 해당 방법에 대한 내용은 뒤에서 차차 다뤄보겠다.
2. 포스팅 논문의 개요
아래 그림은 Masked Language Model (MLM)에서의 pre-training과, fine-tuning, 해당 논문에서 제시하는 방법을 나타낸 그림이다.

위의 그림에 따르면 기존의 fine-tuning 방식 (b)는 model dimension 의 2배만큼의 parameter를 학습시켜야한다. 이러한 파라미터의 재학습은 학습 데이터가 적은 few-shot 상황에서 모델의 성능을 저하시키고, 오버피팅을 일으키는 원인이 된다. 하지만 prompt-based fine-tuning은 파라미터의 재학습없이 진행된다는 장점이 있다.
위 그림의 (c)는 해당 논문에서 제시하는 방법을 보여줌과 동시에 기존의 prompt-based fine-tuning에 대한 overview를 준다. prompt-base fine-tuning 방법은 입력,template(레이블),demonstration(예시)로 이루어져 있다. 모델은 input에 맞게 template의 빈칸(label)을 맞추는 방식이고, template의 뒤에는 각 label의 demonstration를 함께 붙여줌으로써 template를 채우기 위한 정보를 제공하고 있다.
다시 한. 번 강조하지만, 해당 논문은 위와 같이 정해진 prompt-based fine-tuning 방식에서 사용되는 prompt와 demonstration을 ㅏ자동으로 생성해주는 것에 contribution이 있다.
3. Prompt 자동 생성
먼저 prompt 자동 생성에 대해 알아보자.
논문에서는 좋은 prompt를 design하는 것에는 해당 task의 도메인 전문가와, 여러 시행착오가 필요하며, 이는 상당히 고된 작업이라고 지적하고 있다. 이러한 문제를 해결하기 위해 해당 논문에서는 자동으로 prompt를 design하는 방법을 제안하였다.
우선은 few-shot learning 상황을 가정하기 위해 각 class마다 16개의 sample을 사용하여 training과 development dataset를 구성하였다. (||train_set||=||dev_set||=32)
위에 언급하였듯 prompt는 label words와 template로 이루어져 있는데, label word 자동 생성은 아래와 같은 흐름으로 진행된다.
1) 후보군 생성 : 각 레이블에 대해 레이블이 있는 모든 훈련 예제에서 조건부 확률이 가장 높은 상위 K 단어를 가져옴
2) 조합 생성 및 prune : 생성 가능한 모든 조합을 구하고, 그 조합을 train set의 zero shot 환경에서의 확률을 이용하여 prune

3) fine-tuning을 이용한 re-rank : 이렇게 구한 label word의 조합을 이용하여 fine-tuning을 진행하고, dev set을 이용하여 re-rank를 진행

Template 자동 생성은 아래와 같다.
위의 label word 자동 생성에서 positive - greate, negative - terrible와 같은 label word가 생성되었다고 가정하다. 이제는 template를 생성할 차례인데, 이때에는 T5를 사용하고 있다. 실험 내용을 찾아보니 T5-large-3B를 사용하였다. 이렇게 T5를 이용하여 자동으로 template를 생성한 후, train set에서 fine-tuning을 진행하고, dev set에서 evaluate를 진행하여 best template를 찾는다.

4. Demonstrations 자동 매칭
해당 논문에서는 template 못지않게 학습 예제의 역할 혹은 task 설명의 역할을 하는 demonstration이 중요하다고 말하고 있다. 이를 위해서 매 input마다 pretrained sentence-bert를 이용하여, train data안에서 가장 유사도가 높은 문장을 demonstration으로 이용한다고 말하고 있다. 너무 적어서 당황했는데.. 어쨋든 핵심은 이것이 맞다...

5. 실험
실험이 매우 많다. 하나하나 차근차근 보자.

Table 2는 적절한 template과 label word를 선택하는 것의 중요성에 대한 실험이다. 상단의 실험에서 great/terrible와 good/bad, terrible/great의 결과를 비교함으로써 적절한 label word의 선택의 중요성을 확인할 수 있다. 하단의 실험은 상단의 실험과 비교했을 때에 template에 초점이 맞춰져있다. 여러 형태의 template가 존재하는데, 적절한 template을 선택하는 것이 성능에 영향을 끼친다는 것을 알 수 있다. 전반적으로는 좋은 실험이라고 생각하지만, 논문에서는 prompt(template, label word)와 demonstration을 다루고 있는데, prompt에 대한 비교 실험만 존재하고, demonstration에 대한 실험은 존재하지 않아 아쉬웠다.

다음으로 table 3는 어찌보면 이 논문의 주된 실험 결과 정리라고 볼 수 있을텐데, 제시하는 방법들이 수동으로 prompt를 생성해낸 방법들과 비교했을 때 어느정도 비슷한 성능을 보여주고 있다. 한가지 흥미로운 점은, demonstration의 경우 언제나 성능 보장을 보여주지 않는 다는 점이었다. 또한 CoLA쪽 칼럼을 보면 prompt-based fine-tuning이 적은 sample을 이용한 fine-tuning보다 좋은 성능을 보여주지 못하고 있다.
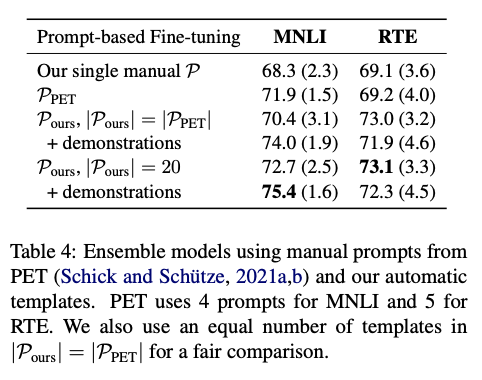
다음 table 4는 manual prompt와 ensemble 실험인데 PET는 4개,5개의 prompt를 사용한 상태이다. prompt의 갯수를 늘렸을 때에 성능 증가가 나타난 다는 것은 쉽게 알 수 있으나, demonstration의 추가가 성능 증가를 보장하지 않는다는 점은 위의 table3의 실험 결과와 유사한 경향성을 보여주고 있다.

Table 5의 실험도 제안하는 방법이 무조건 좋다는 것을 보여주지는 못한다. 다만 Manual하게 생성한 prompt보다 automatic하게 생성한 prompt의 결과라는 점에서는 어느정도 납득할만도 하다고 생각했다.

Table 6는 자동으로 생성한 template와 label words의 예시를 보여주고 있다. 논문의 main contribution은 prompt와 demonstarations의 자동화인데.. prompt만 보여주고, demonstrations는 왜 안보여주는지 잘 모르겠다..
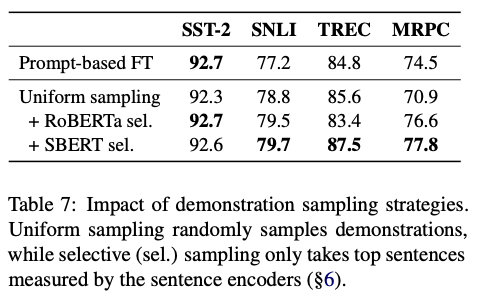
Table 7은 demonstration의 sampling 전략으로 어떤 방법이 좋은지를 논하는 것인데, sentence bert를 쓰는 것이 좋았다는 결론으로 귀결된다.

Figure3는 일반적인 fine tuning 방식과의 few-shot learning 성능을 비교하는 실험인데 training sample의 수인 K가 증가할 수록 제안하는 방법인 LM-BFF가 더 좋은 성능을 보여주고 있다.
6. 결론
아쉬운 논문이었다. Template 생성에서의 T5와 Demonstration의 sampling에서 sentence bert를 사용하였는데, 이렇게 할거였으면.. 처음부터 T5를 사용해서 이것저것 하면 되지 않았을까 하는 아쉬움이 있다.
'Machine Learning' 카테고리의 다른 글
| 파이썬을 활용한 베이지안 통계 를 읽고 나서 (2) | 2022.07.24 |
|---|---|
| 따라하며 하는 Slurm 세팅 & 설명, Ubuntu 18.04 (4) | 2021.04.18 |
| 코싸인 어닐링,Cosine annealing learning rate scheduler 간단 설명 (1) | 2020.12.13 |
| GPT-3 paper를 읽고 써보는 간략한 리뷰 혹은 설명, Language Models are Few-Shot Learners (0) | 2020.09.06 |
| 추천 시스템(Recommendation System) - 협업 필터링 (Collaborative filtering) 설명 (1) (0) | 2020.07.19 |


